Build your own Search Engine from Scratch in Java

Dec 30, 2023

Photo by BoliviaInteligente on Unsplash
Inthis article, we'll be creating our very own search engine called Orbit in Java from scratch. Yes, you heard it right; we'll be creating an application that will take a webpage URL similar to what Google webmaster does, will crawl it and will index it. After that, we can feed in the query, and it will throw us the results. Sounds Interesting? Let's jump into it.
If you don't understand what crawling or indexing means, no worries; we'll be diving deep into each of these terms. I'll walk you through the thought process and the code so that you can create your very own search engine, or you can simply go to Github and fork the codebase and help yourself.
Basics of Searching
Alright, Let's start with the basics of searching. Let's say you are given a phone book, and you are asked to search for the name, say, Kishan. The only catch is that the pages are jumbled, which means names starting with K can be anywhere. What will you do?
Well, the only option we are left with is to go manually over each page and look for that cool name. You see, things will be faster if there are only, say 10 pages, but it will get tougher and tougher as we increase the number of pages to 1000 or even 10,000.
But let's think for a moment: what if we had the pages in sorted order? or, heck, even if we had a table of contents that could tell us which page to go to for names starting with K?
If that were the case, the whole search process would be done in mere seconds, don't you think? No matter how many pages there were, all we needed to do was to just go to that page number, and we were done. This process is termed Indexing. In more formal terms:
You see, the Internet is a large collection of websites; hundreds if not millions of pages are added each day, and Google or Bing can retrieve the information in a fraction of a second. The pages are stored somewhere, right? Yes, they are stored in DBs, and if there is no indexing, no matter how much computation power we throw at searching, it will take hours, if not minutes. This is how Indexing is.
Alright, so how do we index a webpage?
Okay, before going deep into the implementation, let's take a step back and think about what will be our purpose of indexing.
Our purpose, should we accept it, is to retrieve the relevant web pages if a user searches for a certain term. For e.g., If I am typing "Cosmos" in Google search, I should be getting all the results of webpages that talk about the cosmos, right?
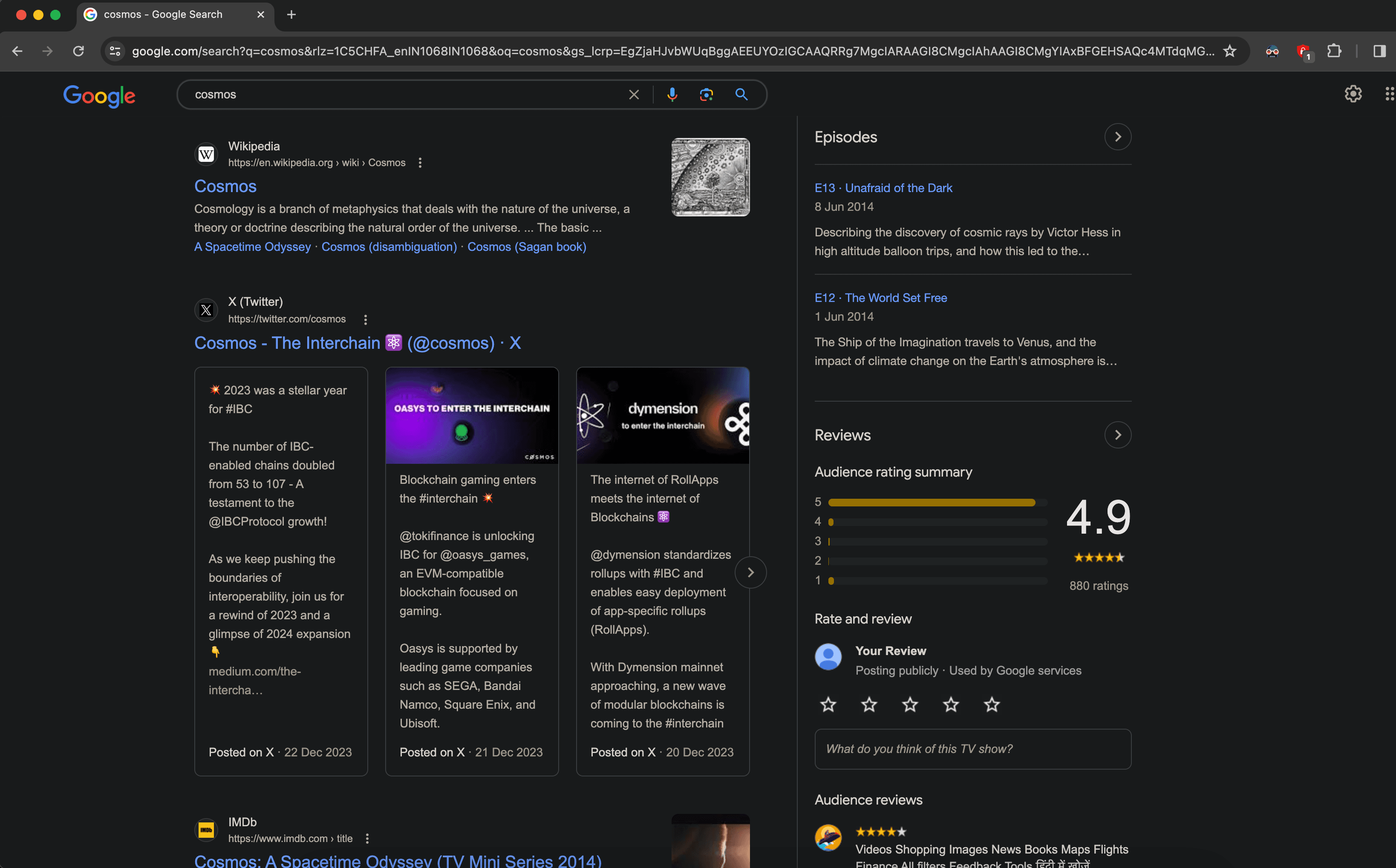
Search result of Cosmos
In the above screenshot, we can see that Google throws about millions of web pages and ranks them based on some algorithm. More importantly, all these web pages will definitely contain the term "Cosmos" in them.
How are we going to achieve that?
Well, there is a term called Inverted Index. Where we store the term and all the websites it has appeared on.
For e.g:
1{
2 "cosmos": ["www.wikipedia.org/cosmos", "www.imdb.com/cosmos", ...]
3}Think of it as a map of terms vs all the websites that it has appeared on. We call this data structure an Inverted Index.
So if somebody searches for cosmos, we'll look into our index and throw them all the websites that we have seen so far. But wait a minute, how do we decide the order? Because it is the most important aspect, right? Yeah, I know, but explaining that would take a whole year. Just kidding, we'll cover that important stuff in our future article. In this article, all we'll do is to give them all the results present in the list. No ordering because we don't discriminate.
Enough blabbering. How are we gonna build it?
Well, on the scale at which Google operates, this index can't be stored in one place, heck, not even in one data center. They'll need sharded databases (NoSQL) to store such a high volume of data. But since we are just starting out, we'll store this information in memory. HeHe.
Okay, let's divide the process:
- Fetch the content of the webpage (which will be done by our crawler, discussed later in detail).
- Preprocess the content. For example, convert the content to lowercase. Why? Because we don't want to store "Think" and "think" as two different terms.
- Split the content into words or what is called Tokens in NLP (Natural Language Processing).
- For each word, go through a process called lemmatization / stemming.
- Remove the stop words, punctuations, special characters, etc.
- Build the Inverted Index.
I think it would be better to show you an example to just explain each term. Following is content from a webpage that doesn't exist. It talks about some universe and stuff:
Step 1: First, we'll fetch the content, and we get:
Step 2: Preprocess the content
Step 3: Split the content into words or tokens
Step 4: Lemmatization: It is a process of reducing a word to its base or dictionary form, known as lemma. But why would we do that? Because if we don't, the computer will consider think and thinking as two different words, which actually aren't.
Step 5: Remove the stop words, punctuations, special characters, etc.
Step 6: The most important part is where we build the Inverted Index. Here, we take each term and map that to the corresponding website it appeared on.
1{
2 "universe": [
3 "http://www.universe.com"
4 ],
5 "everything": [
6 "http://www.universe.com"
7 ],
8 "exists": [
9 "http://www.universe.com"
10 ],
11 "smallest": [
12 "http://www.universe.com"
13 ],
14 ...
15 ],
16 "holes": [
17 "http://www.universe.com"
18 ],
19 "matter": [
20 "http://www.universe.com"
21 ],
22 "dark": [
23 "http://www.universe.com"
24 ],
25 "energy": [
26 "http://www.universe.com"
27 ]
28}So, now, if anybody wants to search for, say, "energy", we'll look into this map and will return the website: "http://www.universe.com".
Please note: I have oversimplified it a bit so that it is easy to comprehend.
Let's code our Engine
Since I am using Java, I'll be using the Dropwizard framework. It's quite intuitive to follow. If you'd like to learn more about it, I have written a detailed article to get started with it.
Learn Dropwizard: A Practical Guide to Developing REST APIs with Java
Dropwizard is an opensource Java framework for building scalable RESTful web services, microservices, and bundles

Let's first understand what APIs we'll be exposing.
- We would want users to come and submit their website to our search engine. This is similar to what Google webmaster does. You manually go and ask Google, hey, this is my wonderful website, and I'd like it to get indexed the next time somebody searches for it. Can you crawl and index it, please?
- When the user submits their website, the crawlers or simply servers scrap the website, go through all the processes that we explained above, and index it.
- We would also want our users to search by providing the query.
So, all we need is two APIs.
Crawl API
1POST /crawl?url=http://0xkishan.com&crawlChildren=falseThe crawl api will take two query parameters:
- url: the website that you want to get indexed onto our search engine
- crawlChildren: whether you want the links that are present inside the URL to be indexed as well?
Here's the code for this. I have called this class Webmaster, and it exposes an endpoint /crawl where the user can submit the URL to be indexed.
1@Path("/")
2@Tag(name = "Webmaster APIs",
3description = "Use these APIs to crawl a website and make it indexable")
4@Produces("application/json")
5@Consumes("application/json")
6@AllArgsConstructor(onConstructor = @__(@Inject))
7@Slf4j
8public class Webmaster{
9 private Crawler crawler;
10
11 @POST
12 @Path("/crawl")
13 public Response crawl(@NonNull @QueryParam("url") final String url,
14 @DefaultValue("false") @QueryParam("crawlChildren") final boolean crawlChildren) throws Exception {
15 try {
16 long start = System.currentTimeMillis();
17 crawler.crawl(url, crawlChildren, 0L);
18 long end = System.currentTimeMillis();
19 log.info("Successfully crawled the website in :{}ms", (end - start));
20 return Response.ok(200).build();
21 } catch (Exception e) {
22 log.error("Unable to crawl: ", e);
23 throw e;
24 }
25 }
26}Notice that we are calling a class called Crawler. Let's dive into the crawl() method.
1public void crawl(String url, boolean crawlChildren, long depth) {
2 if (depth > crawlingConfiguration.getMaxDepth()) {
3 return;
4 }
5 if (crawledUrls.contains(url)) {
6 log.error("Already Crawled, Skipping...");
7 return;
8 }
9
10 log.info("crawling " + url + "...");
11 // scrape the data from the website
12 HtmlPage htmlPage = getHtmlPage(url);
13 if (Objects.isNull(htmlPage)) {
14 return;
15 }
16 // submit the page to the indexer (worker thread)
17 executorService.submit(() -> indexer.index(buildDocument(htmlPage)));
18
19 List<String> urlsFound = htmlPage.getPage().getAnchors().stream().map(HtmlAnchor::getHrefAttribute).toList();
20 log.info("total urls found in: {} is: {}", url, urlsFound.size());
21
22 List<String> validUrls = filterMalformedUrls(urlsFound);
23 log.info("total valid urls found in: {} is: {} / {}", url, validUrls.size(), urlsFound.size());
24
25 if (crawlChildren) {
26 validUrls.forEach(validUrl -> {
27 try {
28 crawl(validUrl, true, depth + 1L);
29 } catch (Exception e) {
30 log.error("unable to crawl: e", e);
31 }
32 });
33 }
34 crawledUrls.add(url);
35}The crawl method takes three arguments: two are straightforward, but the third one might not be intuitive. It is called depth. When we visit a website, it contains multiple hyperlinks; if we have enabled the crawlChildren, the crawler will crawl those hyperlinks as well, but those hyperlinks might also contain hyperlinks and so on. So it might be possible that this crawler will never stop, and since we are storing the index in memory, we are risking the application getting killed because of OOM (out of memory). So it is better to stop this at an early stage.
If depth is set to 1. It means the crawler will crawl the current website and the hyperlinks just following it, but not more than that.
Also, there can be a possibility where one website links to another and another website links it back. Thus causing a cyclic dependency. In this case, it will be better to store the URL in a Set, and before crawling the website, simply check the set to see if this website has already been crawled. This will save us some computation power.
But note that this is not how it is implemented in Google. It is highly likely that you update your webpage frequently, and you would want the crawler to index the new content. But for simplicity, let's not allow the websites if they have been crawled already.
You'll also notice that I am calling a method called getHtmlPage(). This is our scrapper, actually. It brings us the content of the page in HTML format. Here, I am making use of htmlunit a package. You can find the whole project on Github, so don't worry about the versions and all.
All this method does is just scrape the data from the URL and provide it to you.
1private static HtmlPage getHtmlPage(String url) {
2 HtmlPage htmlPage = null;
3 // fetch the website content
4 try (WebClient webClient = new WebClient()) {
5 webClient.getOptions().setCssEnabled(false);
6 webClient.getOptions().setJavaScriptEnabled(false);
7 htmlPage = webClient.getPage(url);
8 } catch (IOException e) {
9 log.info("Unable to fetch the page at {}", url);
10 }
11 return htmlPage;
12}After fetching the data, what do you think we should be doing? Yes, exactly, Indexing. Since indexing is a computationally expensive process, we delegated this task to a worker thread.
1executorService.submit(() -> indexer.index(buildDocument(htmlPage)));But the indexer doesn't expect an HTML page but a document that contains the body of the website and some other information, such as the URL, id, etc., for that, we first call buildDocument()
1private Document buildDocument(HtmlPage htmlPage) {
2 return Document.builder()
3 .id(UUID.randomUUID().toString())
4 .title(htmlPage.getTitleText())
5 .url(htmlPage.getBaseURI())
6 .body(htmlPage.getPage()
7 .getBody()
8 .asNormalizedText())
9 .build();
10}After this, we check for all the hyperlinks present in the current webpage. If the hyperlink is valid and the user has enabled it, crawlChildren we crawl those hyperlinks as well till we reach the depth.
Now, let's look into how indexing is working under the hood. We called the index() method of the Indexer.java class.
1public void index(Document document) {
2 // ENTRY POINT
3 long start = System.currentTimeMillis();
4 List<String> tokens = tokenize(document.getBody());
5 generateInvertedIndex(document, tokens);
6 long end = System.currentTimeMillis();
7 log.info("Successfully indexed document with id: {} in {}ms", document.getId(), (end - start));
8}Here, we first tokenize the content. This method does all those preprocessing that we discussed earlier. Note: we are not doing all those laborious tasks ourselves. Rather, we are making use of the Stanford NLP library. Again, all the packages are available on my GitHub repo so that you can check them out.
The code is heavily commented on so that you can understand it line by line. In this method, we are lemmating the token and removing the invalid tokens. private List
1private List<String> tokenize(String corpus) {
2 // convert the corpus to lowercase
3 Annotation annotation = new Annotation(corpus.toLowerCase());
4 pipeline.annotate(annotation);
5
6 // Extract tokens and lemmata from the annotation
7 List<CoreLabel> tokens = annotation.get(CoreAnnotations.TokensAnnotation.class);
8
9 // Build a list to store the results
10 List<String> tokenized = new ArrayList<>();
11
12 // Append the lemmatized tokens to the list
13 for (CoreLabel token : tokens) {
14 String lemma = token.get(CoreAnnotations.LemmaAnnotation.class);
15 tokenized.add(lemma);
16 }
17
18 // remove the stop words from the tokenized words
19 return tokenized.stream().filter(token -> !invalidToken(token)).collect(Collectors.toList());
20}Post this, we create our InvertedIndex. Note that we are using an in-memory hashmap for this instead of storing this index to a datastore, since the amount of data is less.
1// term -> [dc1, dc2],
2private final static Map<String, Set<String>> IN_MEMORY_INDEX = new HashMap<>();
3// dc1 -> document object (containing url, title etc)
4private final static Map<String, Hit> HIT_MAP = new HashMap<>();1public void generateInvertedIndex(Document document, List<String> tokens) {
2 final String documentId = document.getId();
3 tokens.forEach(token -> {
4 if (!IN_MEMORY_INDEX.containsKey(token)) {
5 IN_MEMORY_INDEX.put(token, new HashSet<>());
6 }
7 IN_MEMORY_INDEX.get(token).add(documentId);
8 });
9 HIT_MAP.put(documentId, Hit.builder()
10 .id(documentId)
11 .title(document.getTitle())
12 .url(document.getUrl())
13 .build());
14 }Here, we are going over each token and checking if that exists in the IN_MEMORY_INDEX; if it doesn't, we create one entry and put our document, which is nothing but an object that contains the details, such as the URL, the title of the webpage, and a unique ID.
We are also creating a reverse mapping so that we can link the document from its ID. This is done for easy lookups during querying done by the user.
Now, it's time to implement our search API
Search API
1POST /search?query=kishanSearch api is fairly straightforward; all it takes is one query parameter named query. The result will be the list of web pages that contain the word kishan in them.
1@Path("/search")
2@Tag(name = "Search APIs", description = "Use these APIs to search the web")
3@Produces("application/json")
4@Consumes("application/json")
5@AllArgsConstructor(onConstructor = @__(@Inject))
6@Slf4j
7public class SearchEngine {
8
9 private final Indexer indexer;
10
11 @POST
12 @Path("/")
13 public Response search(@NonNull @QueryParam("query") final String query) throws Exception {
14 try {
15 long start = System.currentTimeMillis();
16 List<Hit> hits = indexer.query(query);
17 long end = System.currentTimeMillis();
18 log.info("Successfully search the entire web for your query and it took only :{}ms", (end - start));
19 return Response.ok(hits).build();
20 } catch (Exception e) {
21 log.error("Unable to crawl: ", e);
22 throw e;
23 }
24
25 }
26}We pass the query to the query method inside the indexer class. Here's how it works:
- We first break down the query into words by splitting it.
- We then loop over each word and see if that is present in our IN_MEMORY_INDEX. If it is present, we get the documentIds (a unique ID provided to each webpage).
- We then use the reverse mapping that we created called HIT_MAP to get the complete details out of the ID, such as the URL, title of the webpage, etc.
- We return the collated list of all the web pages that matched the term.
1public List<Hit> query(String query) {
2 // split the word into terms and check in the index if they are present
3 List<String> terms = Arrays.stream(query.toLowerCase().split(" ")).toList();
4 List<Hit> hits = new ArrayList<>();
5 if (terms.isEmpty()) {
6 return hits;
7 }
8
9 terms.forEach(term -> {
10 if (IN_MEMORY_INDEX.containsKey(term)) {
11 Set<String> documentIds = IN_MEMORY_INDEX.get(term);
12 hits.addAll(documentIds.stream().map(HIT_MAP::get).toList());
13 }
14 });
15
16 return hits;
17}Spin up your Search Engine
- Open up IntelliJ IDEA, and click on New, followed by Project from Version Control.
- Paste https://github.com/confusedconsciousness/orbit.git in the URL and click on clone.
- In the top right corner, you'll see a drop-down to edit the configuration. This is where we'll be defining which JDK to use and which configuration to pick up during the runtime.
- Click on the + icon to add a configuration and choose Application.
- Fill in the details such as the JDK version, the main Class, which will be App in our case, and the path to the configuration file, which will be config/local.yml prefixed by the server.
- Now click on the Run icon, and you'll start seeing logs in the terminal.
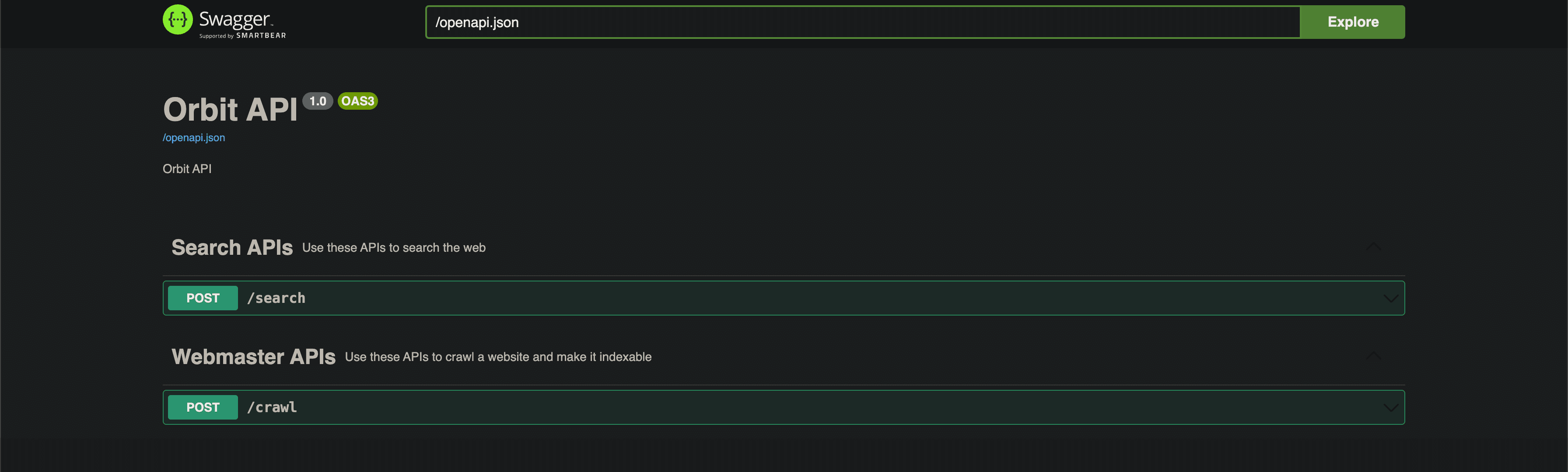
- You'll notice that the server has started on port 9090. Head to localhost:9090/swagger to test those APIs that we talked about.
- You can see there are two APIs present. First, let's crawl any website. For this article, I'll crawl my personal website, but please don't use my website while crawling. 🙏🏽
- I have, for the demonstration, put the crawlChildren to be false, since I don't want to put too much load on my small website.
- In logs, you'll see the logs that the crawler is crawling and indexing the website.
- Let's test out our search API. Let's search for Authentication. And you'll see in the response body the title and url of my website. That's cool, isn't it?









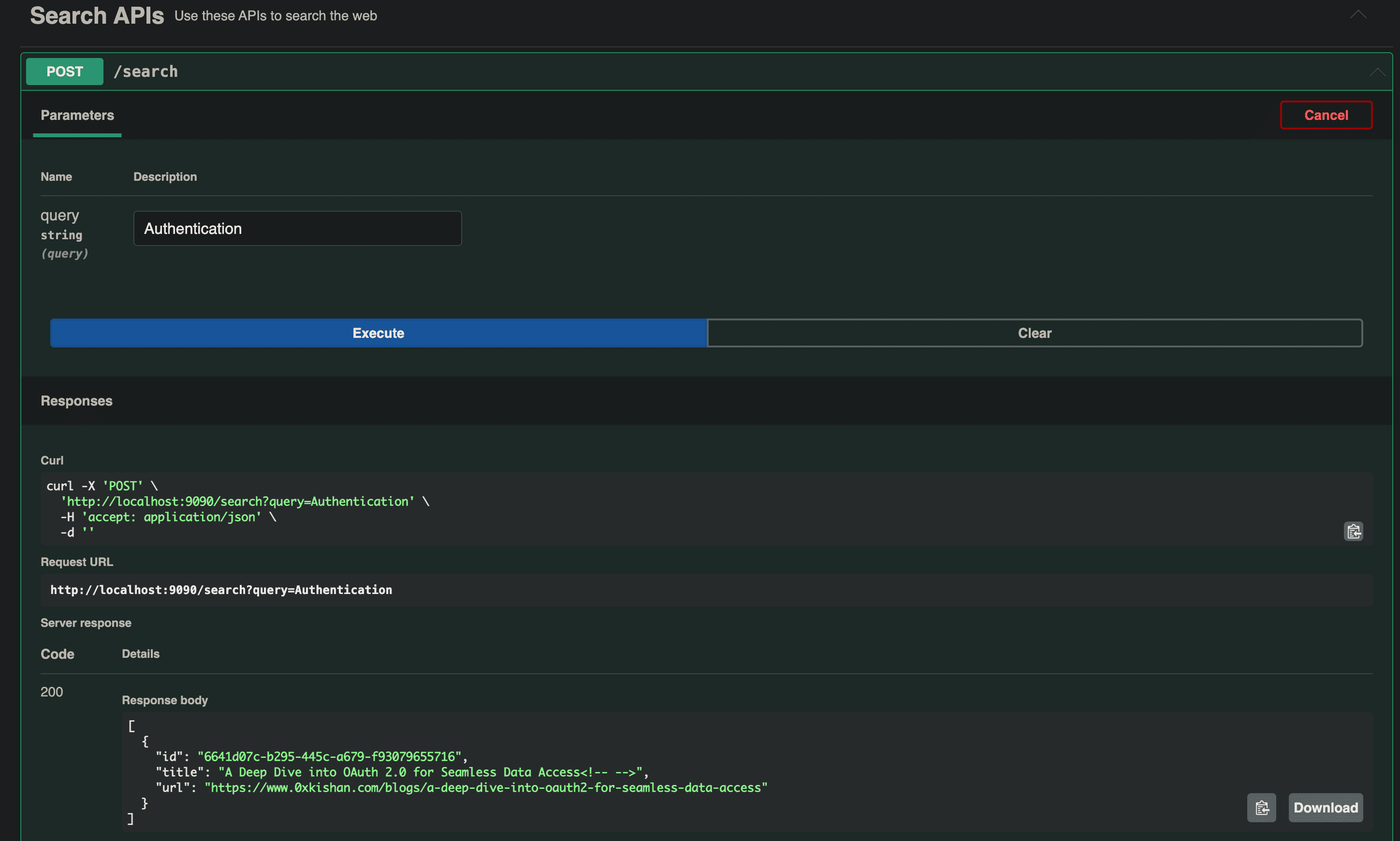
In logs, you'll see something like this:
Alrighty, right! Now it is your turn to test it out. You'd definitely love it. Head over to Github, fork this repo, and make changes or add cool functionality. https://github.com/confusedconsciousness/orbit
Please note: this implementation is overly simplified and high-level, but it gives an overall understanding of how things work under the hood. I hope this article helped you understand the basics of search engines.
Thanks a lot.
The 0xkishan Newsletter
Subscribe to the newsletter to learn more about the decentralized web, AI and technology.
Comments on this article
Please be respectful!