Designing and Implementing a URL Shortener in Java

July 28, 2024

Photo by Google DeepMind on Unsplash
In this article we’ll explore what a URL shortener is, why it is needed, and how we can design it to scale to millions of users. We’ll also be implementing this as a service in Java. Hope you are excited for it. Let’s jump right into it.
Let’s address the elephant in the room first: what is a URL shortener? It shortens URLs, right? Yes, that's exactly what it does—nothing fancy there. But why do we need such a service? Don’t URLs need to convey information, after all?
If we have an URL say:www.0xkishan.com/blogs/design-url-shortener-and-implement-in-java vs www.0xkishan.com/blogs/12fxwg5r
Which link would you click? If I were you, I’d choose the first link because it clearly indicates what I’m clicking on.
But what if I had to share this link on a platform like Twitter, where each character matters? That scenario changes things—I’d opt for the second link. Another question: which link would impersonators and malicious actors use? They might provide a shortened URL, claiming it leads to a nice blog like this, but it could end up capturing personal details.
As you can see, there are pros and cons to using URL shorteners. So, let’s get the definition out of the way. In more formal terms:
A URL shortener is a service that takes a long URL and creates a shorter, more manageable link that redirects to the original URL. This is useful for sharing links on platforms with character limits, making URLs more visually appealing, and tracking click-through rates.Before diving into how are we going to build a service like this, let’s go over some functional (FR) and non-functional requirements (NFR).
First, what are the things that we definitely want out of our service?
Functional Requirements
- Provided an URL, our urlshortener service should generate a unique and shorter urls.
- When a user pastes this shortened links in address bar, they should be redirected to the original link.
- Optional, user should be given an option to choose a custom shortened link for their URL, for e.g. instead of random 12fxwg5r that we showed just above they can very well choose mylink5.
- Optional, the shortened links should get expired after a default timespan.
Non-Functional Requirements
- The system should be highly available. Why? Because if it is down, all the URL redirection will fail and the users will get Timeouts.
- The redirection should happen in real-time with minimal latency.
- The system should have some form of analytics and visualization around the links, such as tracking the number of clicks.
Once we have cleared our requirements, we should think about the estimations and constraints that we may encounter.
For e.g. what will be the traffic estimates? How many new short links are we expecting to generate daily? How many redirections are we anticipating.
Back-of-the-Envelop Estimations
It is evident that our system will be read-oriented, because once we generate the short link we would share it to the world, and the world will be redirected to our awesome article. One write operation and many read operations. Let’s assume a 100:1 ratio between read and writes. This might be an overestimation, but it helps in planning for scalability.
Now is the time to understand how many new short urls will be generated keeping the scale in mind. If we are just starting this business maybe only 1 short link gets generated but we don’t design system keeping today in mind but the future.
Assuming we get popular overnight, we could expect upto 100 short link generated per second.
1New URLs shortening per second: 100 URLs/s If we consider our reads it’ll be 100 * 100 = 10,000 redirections per second.
All these new URLs need to be stored somewhere, right? Yes, and for how long should we keep them? Should we delete the links eventually? If we don't, our storage needs will continuously grow. However, deleting links might upset some users, especially if they are popular and rely on our shortening service. We need to decide on a policy. For instance, we could inform users that their shortened URLs will expire after five years.
Alright, say we chose to persist the data for 5 years. What would our storage requirements be?
Storage Estimates: Let’s assume that we are going to store every URL shortening request for 5 years. Since we are expecting a 100 new urls per second, the total number of urls that we have to deal in 5 years is going to be around:
1100 URLs/second * 60 seconds/minute * 60 minutes/hour * 24 hours/day * 30 days/month * 12 months/year * 5 years = 15 billion URLsLet’s assume that each stored object (both the original url as well as the shortened url) along with some metadata is around 1000 bytes. We will need then 15 billion * 1000 bytes ⇒ 15 trillion bytes ⇒ 15 TB.
Here’s a cheat sheet for you to convert bytes to KB, MB, GB, TB
- 1 million bytes = 1 MB
- 1 billion bytes = 1 GB
- 1 trillion bytes = 1 TB
So, to store short URLs at our current rate, we’d need approximately 15 TB of storage. Given that storage is relatively cheap today, we can provision a buffer of 1.5 times to be on the safer side.
Bandwidth Estimation: Let’s come to the bandwidth that our system will be handling. Since we are expecting a total of 100 new URLs to be created every second, total incoming data (ingress) for our service will be 100 * 1000 ⇒ 100,000 bytes per second or 100 KB/s.
For read request, since we assumed our system to be 100:1, the read request bandwidth (egress) will be 100 * 100 ⇒ 10,000 KB/s ⇒ 10 MB/s.
It is always better to cache some result isn’t it? Since we know that our system is read heavy we can cache some of the short url links in our memory itself and serve it from there itself. This will reduce the load on our systems.
Without caching, handling around 10,000 read requests per second would require the system to repeatedly query the database to map short URLs to their corresponding long URLs, which could strain the database. To alleviate this, we can cache "hot" URLs that are frequently accessed. How much memory would we need for this?
If we follow the 80-20 rule, which means that 20% of the URLs (redirections) are generating the 80% of the traffic. It would make sense to cache those 20%.Since we are getting around 10,000 read request per second, 20% will be 2000, and let’s say we are going to use some sort of eviction policy such as LRU (least recently used) to evict those urls that have not been read for a day.
If we are thinking of handling that much traffic in memory for a day that will amount to 2000 * 86400 (seconds in a day) * 1000 (bytes) = 864 * 2 * 10^8 bytes = 172.8 billion bytes = 172.8 GB.
Thus, to cache the most frequently accessed URLs and reduce database load, we would need approximately 172.8 GB of memory. This would enable our system to handle a substantial amount of traffic efficiently.
Let’s Define APIs
Since we're creating a RESTful service, we'll provide endpoints for users to shorten their URLs and to redirect to the original URLs using the shortened links.
In our case, we’ll be using REST (REpresentational State Transfer) APIs.
Short API
1POST /shorten?url=www.0xkishan.com/blogs/design-url-shortener-and-implement-in-java&alias=urlshortThis API takes two query parameters
- url: the original url that the user intends to shorten
- alias: the short link that the user wants to be used instead. Note: providing a custom alias might not always work, it is like username, if it is not available the user will get error that this alias is taken.
Returns: This API returns a string which is the shortened url. If we were using a short url service such as tinyurl, it returns tinyurl.com/ {shortened - url }
Now there can be challenging task as well, how are you going to prevent abuse? If this API doesn’t have a session or anything any script or malicious user can overwhelm your service.
To prevent this, we can put our service behind an API gateway. Most gateways come equipped with rate limiters and powerful AI detection tools. Another solution would be to require users to log into the system to generate a shortened URL, but this could be a hindrance for them, as there are many competitors that allow them to generate shortened links without logging in or providing their credentials.
Resolve API
1GET /{shortUrl}This API takes only one parameter shortUrl: the shortened url that the user wants to resolve and get redirected to the original long URL
Returns: This API basically redirects the user to the long url by sending the following HTTP status code:
- 301 Moved Permanently: This status code indicates that the resource requested has been permanently moved to a new URL. When clients (such as browsers) receive a 301 status code, they should automatically update their bookmarks and links to point to the new URL. This method is often used for permanent URL changes and is beneficial for SEO purposes.
- 302 Found: Originally intended as "Moved Temporarily," the 302 status code indicates that the resource requested is temporarily located at a different URL. Clients receiving this response should continue to use the original URL for future requests. This is commonly used for temporary redirects.
- 307 Temporary Redirect: Similar to 302, but it indicates that the requested resource is temporarily located at another URL, and the client should continue to use the original URL for future requests. Unlike 302, it specifies that the method and the body of the original request should not be altered when reissuing the request to the new URL.
- 308 Permanent Redirect: Similar to 301, this status code indicates that the resource has been permanently moved to a new URL, but it specifies that the request method and body should not change. This is useful for methods other than GET, such as POST.
System Design
The thing we have to focus is on generating unique and short keys for a given url. We have to produce something like this:
| Long URLs | Short URLs |
|---|---|
| https://www.example.com/articles/how-to-build-a-url-shortener-in-java | https://short.ly/aBc123 |
| https://www.exampleblog.com/2024/07/top-10-web-development-trends | https://short.ly/xYz456 |
| https://www.example.com/resources/downloads/complete-guide-to-seo | https://short.ly/dEf789 |
Notice here the base domain is [short.ly](http://short.ly) beacuse it is the one that is providing the shortening service.
The last 6 characters that we see such as aBc123, xYz456, dEf789 these are all the short keys that we intend to generate. How can we generate these?
Hashing
We can compute a unique hash of the long URL using MD5 or SHA256 algorithms. The hash generated can then be encoded using base62 ([A-Z, a-z, 0-9]) format.
How long do we want the shortened url? If we go with 6 characters there is a total 62 ^ 6 ~ 56 billion possibilities. If we go fo 7 character we’ll have 62 ^ 7 ~ 3.5 trillion possibilities.
If we use MD5 algorithm as our hash function, it will produce 128-bit hash value. If we use the base62 encoding, we’ll get a string having more than 22 characters. If we decide to slice off the first 6 characters, it can lead to key duplication. To resolve this, we can choose some other characters out of the encoding string.
To avoid key duplication, we can append the user ID (or any predefined string) to the input URL. However, if the user has not signed in, this could pose a problem. We can simply append some predefined string to the URL and then repeat the process.
This method reduces the likelihood of collisions, but it can be expensive to query the database to check if a short URL exists for every request. A technique called a bloom filter can be used instead. A bloom filter is a space-efficient probabilistic technique used to test whether an element is a member of a set.
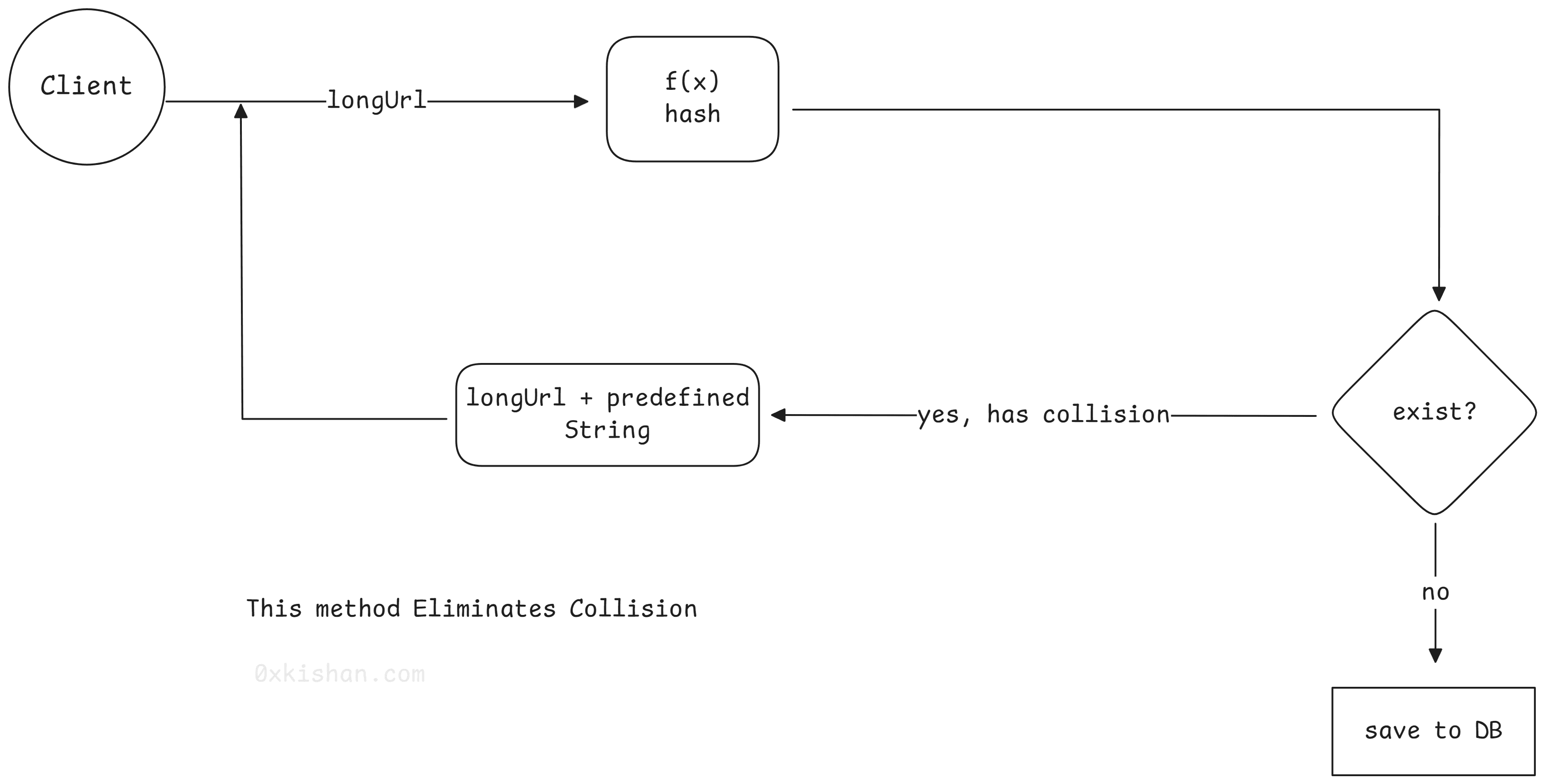
Hashing
Key Generator
We can deploy a unique id generator service similar to Snowflake . . These numbers can reach trillions, and if we base62 encode them, they will always be less than seven characters, which is what we want. Whenever we want to shorten a URL, we will take one of the already generated keys and use it. This approach will make things quite simple and fast. In this scenario, we don’t have to worry about duplications or collisions, as the key generator will ensure all keys inserted into the Key DB are unique.
Since the RPS (requests per second) is quite high, we’ll need multiple instances (horizontal scaling) of the key generator service. We must ensure that the keys generated are not duplicated and that the keys generated by one instance are different from those generated by another instance.
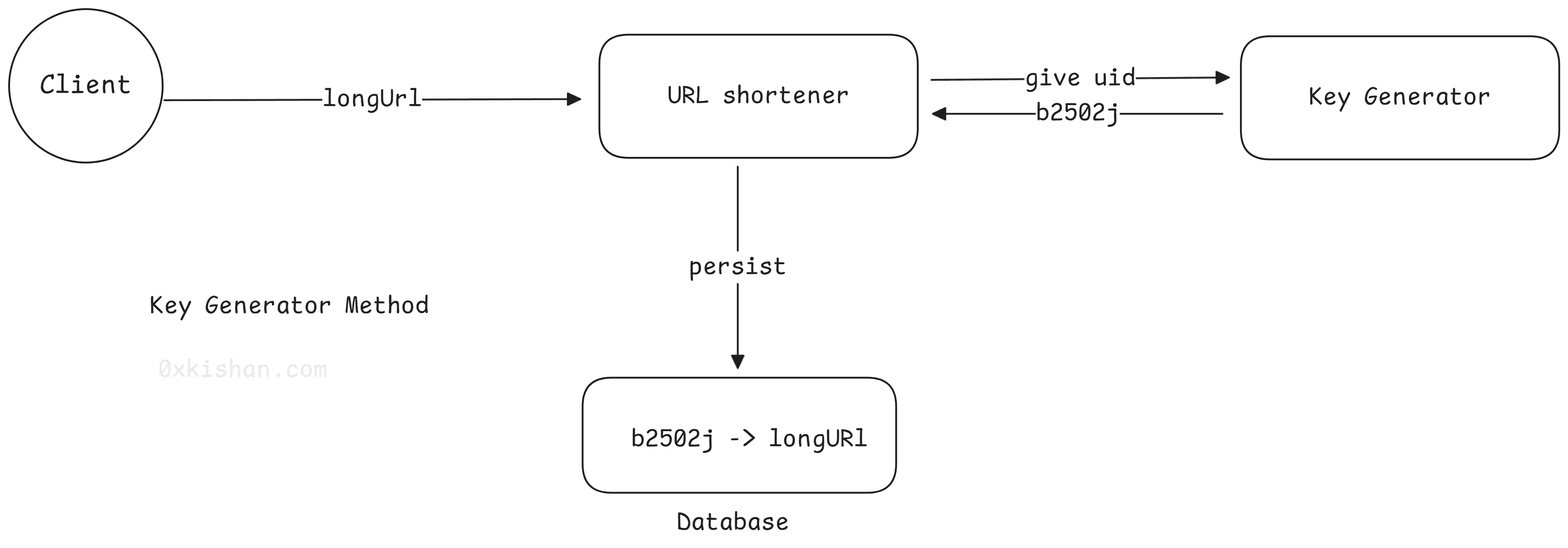
Key Generator Service
| Hashing | Key Generator |
|---|---|
| Fixed short URL length | Short URL length is not fixed. It depends on the length of the key generated by the service. |
| Does not need a unique ID generator | This depends on a unique ID generator. |
| Collision is possible and needs to be resolved. | Collision is not possible since the IDs are unique. |
| It’s not possible to figure out the next available short URL because it doesn’t depend on the ID. | It is possible to figure out the next short URL. |
Data Partitioning and Replication
As we calculated that we’ll be needing around 15 TB of storage and this number can keep on growing we can’t store this data on a single box because of various reason and the biggest would be a single point of failure. If that database crashes all the mapping of long to short URL will be lost and we’ll blank and out of the business.
Also storing all the data on a single place will lead to increased latency while reading the entries. To know more about why that would be the case, you can refer this article that I published a few months back.
Sharding for Beginners: What It Is, Why It Matters, and How It Works
Sharding means breaking down a big dataset into small disjoint subsets

To scale out our DB, we need to partition the data. For partitioning we need to develop the partitioning scheme that would divide our data evenly.
If we are thinking of making use of a key-value store DB (NoSQL) it would be wise to use the consistent hashing to evenly distribute the data across multiple DB servers. You can refer to what consistent hashing is in this article: Consistent hashing is a distributed hashing technique that aims to evenly distribute data across a set of nodes (servers) and minimize the impact of node additions or removals.Consistent Hashing in System Design: An In-Depth Guide
In brief, Consistent hashing is a distributed hashing technique that aims to evenly distribute data across a set of nodes (servers) and minimize the impact of node additions or removals. Here, we take a hash of the object we are storing. We figure out to which particular node does this hash belongs to, we then store the data to that node.
Replication is needed, in case our node crashes that had all the data belonging to a particular hash range. If there were no replication we’ld lose all that data. One of the benefits of replication is that it makes the whole system fault-tolerant. If a primary node fails, the data can still be accessed from one of its replicas, ensuring the system remains operational. Also, replication increases the availability of data, making it possible for multiple nodes to serve read requests simultaneously, thereby improving read performance. By distributing read requests across multiple replicas, the system can balance the load more effectively, preventing any single node from becoming a bottleneck.
Request Flow
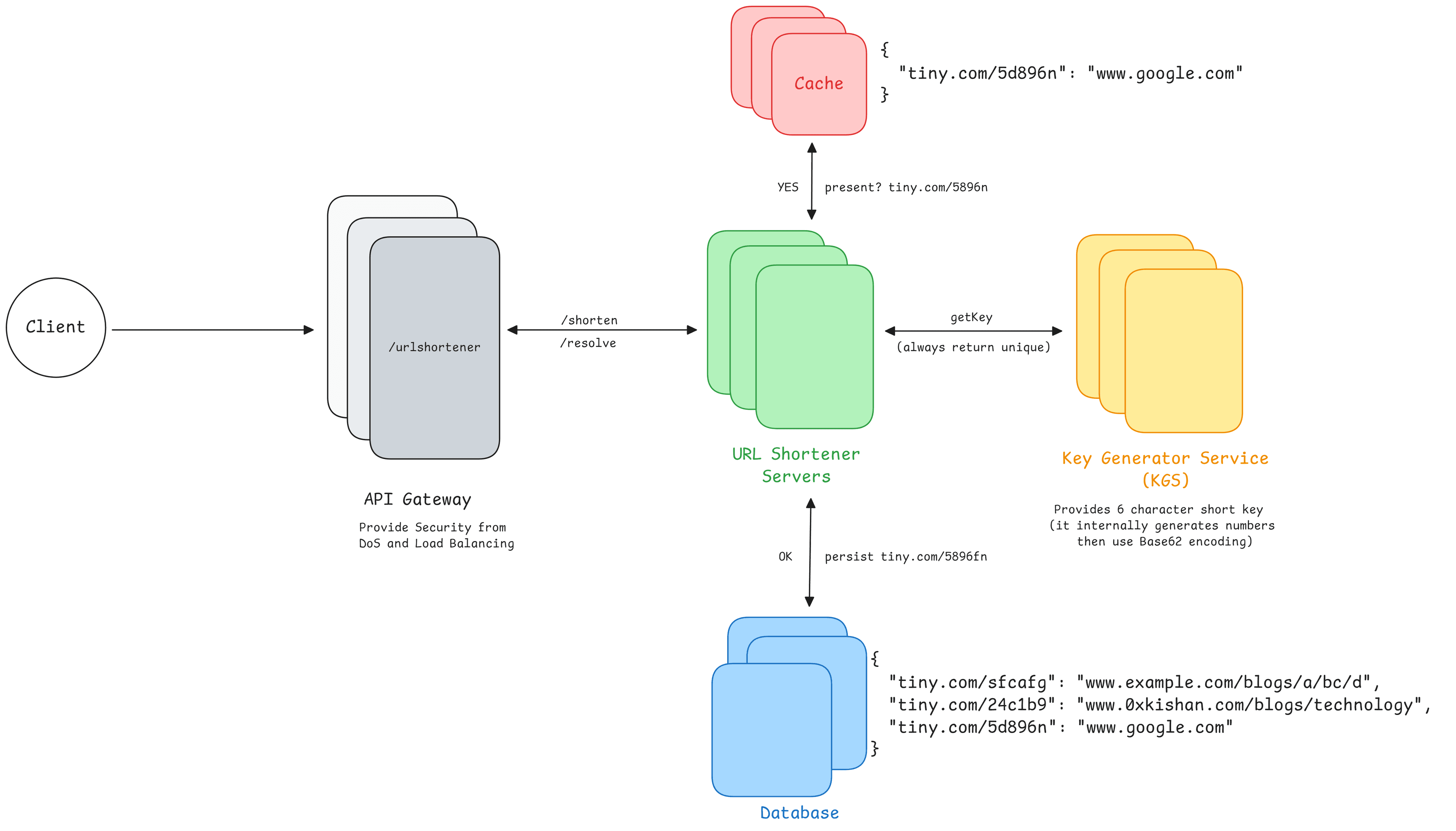
Request Flow
We can cache URLs that are frequently accessed. We can use Redis for our purpose. First the URL shortener servers will hit the cache and if there is a cache miss then only call the database and update cache.
API gateway is a crucial component in microservices architecture, it provides a lot of benefits such as rate limiting, authentication, load balancing, analytics etc.
As explained earlier KGS (Key generator service) provide us with unique key everytime it is called. It is a distributed key generator.
Implementation in Dropwizard Java
If you want to gets your hands on the github repo:
URLShortener GithubPlease note: This repo may get updated to include more features at later point in time. Make sure to follow the updates
We have created two Resource class:
- Resolver: this class helps in redirecting the short url to the original long url
- Shortener: this class helps in creating the short url.
1package com.kishan.resources;
2
3@Path("/")
4@Tag(name = "URL Resolver APIs", description = "Use these APIs to resolve short URLs to long URLs")
5@Produces("application/json")
6@Consumes("application/json")
7@AllArgsConstructor(onConstructor = @__(@Inject))
8@Slf4j
9public class Resolver {
10
11 private final UrlShortener urlShortener;
12 @GET
13 @Path("/{shortUrl}")
14 public Response resolve(@NonNull @PathParam("shortUrl") final String shortUrl) throws Exception {
15 try {
16 // resolve the urls
17 String longUrl = urlShortener.resolver(shortUrl);
18 return Response.temporaryRedirect(URI.create(longUrl)).status(307).build();
19 } catch (Exception e) {
20 log.error("Unable to Resolve your URL: ", e);
21 throw e;
22 }
23
24 }
25}
26As you can see we have a method names resolve, that takes path param which is the shortKey that we provide the client. It calls the UrlShortener which we’ll talk about it in a minute and it returns the original long url. We then return Response with temporaryRedirect with status code 307.
Shortener.java1package com.kishan.resources;
2
3@Path("/shorten")
4@Tag(name = "URL Shortener APIs", description = "Use these APIs to shorten your long URLs")
5@Produces("application/json")
6@Consumes("application/json")
7@AllArgsConstructor(onConstructor = @__(@Inject))
8@Slf4j
9public class Shortener {
10
11 private final UrlShortener urlShortener;
12
13 @POST
14 @Path("/")
15 public Response shorten(@NonNull @QueryParam("url") final String url, @QueryParam("alias") final String alias,
16 @QueryParam("type") @DefaultValue("HASHING") final EngineType type) throws Exception {
17 try {
18 // allow the user to choose an alias
19 String shortenUrl = urlShortener.shorten(url, alias, type);
20 return Response.ok(Json.pretty(shortenUrl)).build();
21 } catch (Exception e) {
22 log.error("Unable to shorten your URL: ", e);
23 throw e;
24 }
25
26 }
27}
28This class takes the long url and alias as query param and returns the shortenUrl on which if you visit you’ll be redirected to the original long url. You might also notice that it takes one more parameter called type. By default it is set as HASHING, this means it will at the backend use the hashing algorithm with collision avoidance. You can tweak it to use different algorithm that we discussed above.
If you run the above dropwizard application and go to localhost:9090/swagger you’ll see the following two APIs. How do I run the dropwizard application? You can refer other article on setting up and running the application.
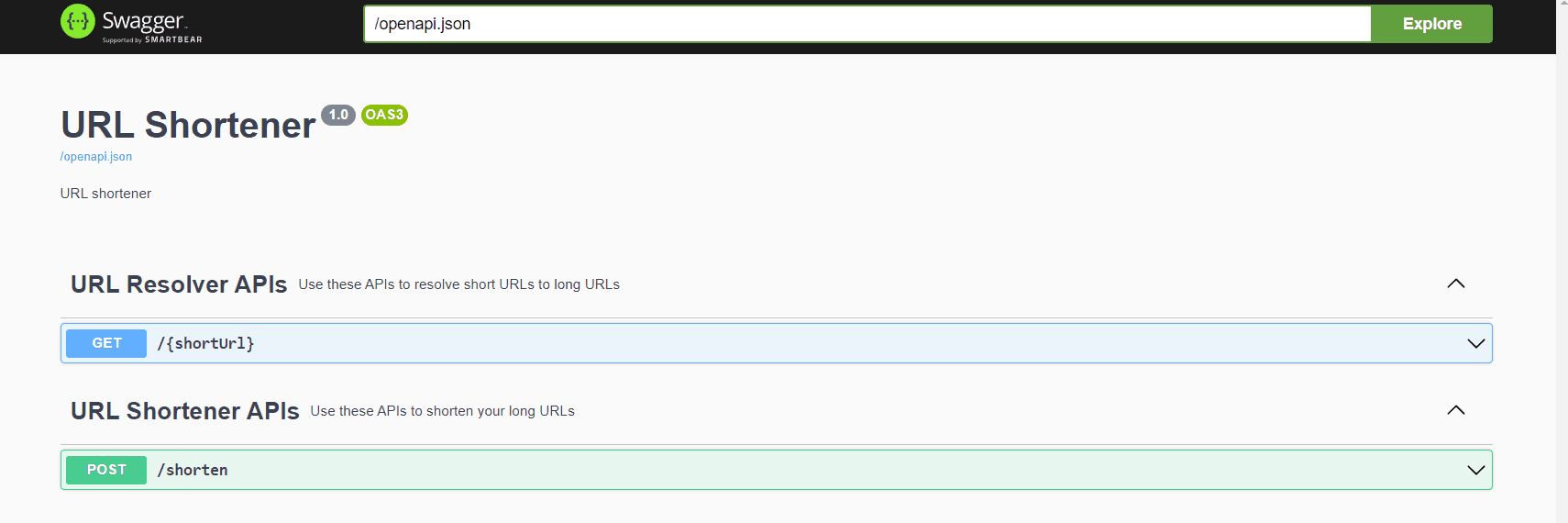
Key Generator Service
Let’s talk a little about the UrlShortener. This service is responsible for talking to different engine (Hashing and KeyGenerator) depending upon the type you choose. Notice we are not storing these data in the DB everything is done in-memory. We have created a class called DB.java that is nothing but an in-memory concurrent hashmap.
UrlShortener class has two public method:
- shorten: as the name implies, it takes the longUrl and the alias and returns the shorten url. Notice we are not simply returning the shortened key but we are appending to the base url which will be the domain of the application in our case it is localhost:9090.
- resolve: this takes shortUrl and returns the complete long url.
1package com.kishan.core;
2
3@Slf4j
4@Singleton
5@AllArgsConstructor(onConstructor = @__(@Inject))
6public class UrlShortener {
7 private final EngineFactory factory;
8 private final UrlShortenerConfiguration urlShortenerConfiguration;
9
10 /**
11 * Takes longUrl and alias (readable short url) and returns the shortened URL
12 *
13 * @param longUrl (the original long url that needs to be shortened)
14 * @param alias (human readable short link_
15 * @return shortUrl (string)
16 */
17 public String shorten(String longUrl, String alias, EngineType type) {
18 // this needs to be thread safe
19 if (!Strings.isNullOrEmpty(alias) && DB.cache.containsKey(alias)) {
20 // this alias is already taken throw error
21 throw new IllegalArgumentException("Alias already exists");
22 }
23 // if the user has provided an alias, we should honor that and should not invoke key generator
24 String shortKey;
25 if (Strings.isNullOrEmpty(alias)) {
26 shortKey = factory.getEngine(type).getUniqueKey(longUrl);
27 } else {
28 shortKey = alias;
29 }
30 // fetch the unique key from the KGS
31 // update the DB/Cache (here we are storing everything in memory)
32 DB.cache.put(shortKey, longUrl);
33 return String.format("%s/%s", urlShortenerConfiguration.getBaseUrl(), shortKey);
34 }
35
36 /**
37 * This finds whether there exists shortUrl, if exists it finds the corresponding long url and redirect it
38 *
39 * @param shortUrl: the url provided by the service in the exchange of long url
40 * @return long url
41 */
42 public String resolver(String shortUrl) {
43 try {
44 String longUrl = DB.cache.get(shortUrl);
45 if (Strings.isNullOrEmpty(longUrl)) {
46 log.error("No such entry present corresponding to {} URL", shortUrl);
47 throw new IllegalArgumentException("No such URL exists");
48 }
49 return longUrl;
50 } catch (Exception e) {
51 throw new IllegalArgumentException("Malformed URL");
52 }
53 }
54
55
56}
57Let’s talk about the EngineFactory.java class. This class returns the algorithm instance that we want to use in order to create the short url. EnginerFactory class returns an instance of Engine.java an abstract class that is being extended by two classed called HashingEngine.java and KeyGeneratorEngine.java. The base class has only one public method called getUniqueKey(string) that returns you unique keys.
These unique keys are different depending on what engine we are using. If we are using KeyGeneratorEngine, then we'll get bas62 encoded numbers. The numbers are always increasing and each KeyGeneratorEngine service will have a machineId to distinguish itself from other instances. This machineId also helps it to generate unique ids across the instances because it is also the part of encoding. If we choose HashingEngine, then we compute the MD5 hash of the longUrl and only choose the first 7 character. If there are some collisions, we append an UUID string and hash it again till we get a unique key.
Let's discuss the KeyGeneratorEngine. We take three things and stitch them together to get a large increasing number: time, machineId, datacenterId and sequence number.
KeyGeneratorEngine .java1package com.kishan.core.engines;
2
3import lombok.SneakyThrows;
4import lombok.extern.slf4j.Slf4j;
5
6/**
7 * KGS: Key Generator Service This class provide us with unique key every time it is called We will
8 * only be having one instance.
9 */
10
11@Slf4j
12public class KeyGeneratorEngine extends Engine {
13 private int sequence = 0;
14 private static final String BASE62 = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz";
15 private final int machineId = 1;
16 private final int datacenterId = 1;
17
18 private String base62(long time, int machineId, int datacenterId, int sequence) {
19 StringBuilder encodedString = new StringBuilder();
20 long modifiedNumber = Long.parseLong(String.format("%d%d%d%d", time, machineId, datacenterId, sequence));
21 while (modifiedNumber > 0) {
22 int remainder = (int) (modifiedNumber % 62);
23 encodedString.append(BASE62.charAt(remainder));
24 modifiedNumber /= 62;
25 }
26 return encodedString.reverse().toString();
27 }
28
29 @Override
30 @SneakyThrows
31 public String getUniqueKey(String url) {
32 // this is done to prevent overflowing
33 // in one millisecond we'll support at max 10000 unique ids.
34 sequence = (sequence + 1) % 10000;
35 // inclusion of datacenterId, and machineId will definitely increase the unique key size by 1,
36 // but it can now support more than ever keys
37
38 // I think there can be duplicates if the processor is able to process more than 10,000 sequence in a millisecond
39 // In that case things will get wrapped up, and we might see duplicates
40
41 // How to avoid that? That will require us to implement thread safe fixed size hashset, which is out of scope
42 return base62(System.currentTimeMillis(), machineId, datacenterId, sequence);
43 }
44}
45The other Engine uses MD5 hash as shown below
HashingEngine.java1package com.kishan.core.engines;
2
3import com.kishan.db.DB;
4import lombok.extern.slf4j.Slf4j;
5
6import java.security.MessageDigest;
7import java.security.NoSuchAlgorithmException;
8import java.util.UUID;
9
10/**
11 * This class is responsible to manage collisions and provide unique key
12 */
13
14@Slf4j
15public class HashingEngine extends Engine {
16
17 @Override
18 public String getUniqueKey(String url) {
19 // only consider the initial 7 characters to be used as short key
20 String hash = MD5(url).substring(0, 7);
21 while (DB.cache.containsKey(hash)) {
22 // this mean a collision has occurred, append some random string
23 log.warn("Collision detected for url: {}", url);
24 hash = MD5(hash + UUID.randomUUID()).substring(0, 7);
25 }
26 // if we are here no collisions found, return it
27 return hash;
28 }
29
30
31 public static String MD5(String input) {
32 try {
33 MessageDigest md = MessageDigest.getInstance("MD5");
34 byte[] digest = md.digest(input.getBytes());
35 StringBuilder sb = new StringBuilder();
36 for (byte b : digest) sb.append(String.format("%02x", b));
37 return sb.toString();
38 } catch (NoSuchAlgorithmException e) {
39 throw new RuntimeException(e);
40 }
41 }
42}
43
44Please visit: UrlShortener on Github and fork/watch it.
The 0xkishan Newsletter
Subscribe to the newsletter to learn more about the decentralized web, AI and technology.
Comments on this article
Please be respectful!